In a previous post, I discussed parametric M-estimators, and proved a consistency result for a large class of such estimators in finite dimensional settings. A lot of the heavy lifting in the proof was done by a compactness assumption. In this post, I will run through some of the basic theory about compact sets that one might encounter in a real analysis course (I was intending to wrap up my discussion of general parametric statistics theory by discussing asymptotic normality results, but I’ve been thinking a lot about compactness lately and wanted to write some thoughts down while they are still relatively fresh in my mind). The goal will be to use these foundations to both get a deeper understanding of why compactness is so important in parametric settings as well as how it hints at the strategies necessary for developing much of the classical theory of nonparametric regression. We begin with the familiar definition:
Definition 1: A subset 


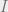



The fact that the sub-cover here is finite provides a hint that compactness is really a property of “smallness” in some topological sense. Why is topological smallness useful in probability? The easiest answer is that it is often easier to estimate the probability of small objects. Let me make this more precise.
Recall the following two axioms of probability:
- If
, the
(monotonicity)
- If
are mutually disjoint, then
where
is possibly infinity (countable additivity)
Exercise 2: Use the above axioms to show that probabilities are countably sub additive:

When
Exercise 3: Let 






The proof of the uniform law of large numbers uses this fact. Compactness allowed us to get a finite set of parameter values 
![P\left(\cup_{i=1}^m\{h(X,\theta_j) - \mathbb E[h(X,\theta_j)] > \delta\}\right)](https://s0.wp.com/latex.php?latex=P%5Cleft%28%5Ccup_%7Bi%3D1%7D%5Em%5C%7Bh%28X%2C%5Ctheta_j%29+-+%5Cmathbb+E%5Bh%28X%2C%5Ctheta_j%29%5D+%3E+%5Cdelta%5C%7D%5Cright%29&bg=eeeeee&fg=666666&s=0&c=20201002)
The discussion above has still been entirely trivial. But what happens when 
Exercise 4: With the notation of exercise 3, show that if 

The above exercise hints that we are able to tolerate mild violations to the “smallness” that compactness gives us and still recover results of interest. As currently stated, however, the idea of a “mild” violation is vague and imprecise. This is only natural as the definition of compactness we are using is itself quite “qualitative” (an easy way to convince yourself that it’s qualitative is to recognize that the definition can be made purely in words: a set is compact if any open cover has a finite sub-cover). However, we will see that there is a more “quantitative” way to characterize compactness in metric spaces. First a set of lemmas:
Lemma 5: Let 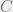
Proof: Fix some open cover of 

Lemma 6: If
Proof: It suffices to show that 








Remark 7: The above proof generalizes exactly if we relax “metric space” to “Hausdorff” by replacing the balls from the above proof with some more qualitative topological concepts. However, since our whole goal here is to develop a more quantitative theory, we will not pursue this generalization here.
Exercise 8: Let 
- For any
, there is a finite set of points
such that
(total boundedness)
- For any
, there exists some subsequence
that converges to a point in
(sequential compactness).
The set of points in total boundedness is sometimes called an 

Total boundedness is of particular interest for the purposes of this post because it highlights the quantitative side of compactness. For a fixed value of
As it turns out, “closed and totally bounded” and “sequentially compact” are both equivalent characterizations of compactness in metric spaces. To see this, it will be useful to first show the equivalence between sequential compactness and closed and totally bounded first:
Lemma 9: Let
Proof: Let us first show 1) => 2). By the definition of sequential compactness, we have that any convergent sequence in 


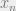







is totally bounded (exercise)
It is clear that for each 



and so on.
Exercise 10: Complete the proof. In particular, show
- A subset of a totally bounded set is totally bounded
- The sub-sequence
,
- By closedness of
Remark 11: The proof of 2) => 1) required a good deal more creativity than the reverse direction, but it boiled down to two standard tricks in analysis:
- Combining the finiteness from total boundedness with the infinite nature of a sequence allowed us to use an infinite version of the pigeonhole principle.
- Using 1, we were able to construct a nested (infinite) array of subsequences. We turned this array into a single subsequence by taking the diagonal elements of this array, a common trick pioneered by Georg Cantor.
Remark 12: Stepping back a bit from the technicalities, the equivalence above stems from the fact that both definitions in a sense restrict our “movement” around the set. Sequential compactness disallows any “escape” to infinity by requiring that eventually, our sequence has to “bump into itself” forever. Similarly, total boundedness restricts escape to infinity by the finiteness of the
The reason why we first showed equivalence of “closed and totally bounded” and “sequentially compact” is that it will actually be easier to show that “closed and totally bounded and sequentially compact” implies “compact”. We will need one more lemma to do the heavy lifting:
Lemma 13 (Lebesgue number theorem): Let 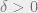



Proof: By contradiction. Suppose no such 








Then we have that 
The Lebesgue number theorem tells us that for every open cover, for some 
Exercise 14: Finish the proof that the following are equivalent in metric spaces:
Exercise 15: Prove that in Euclidean space, totally bounded is equivalent to bounded (a set is bounded if it is contained in some ball of radius 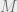



What have we gained for all of this effort? With our original definition of compactness, we had a binary – a set is either compact or not compact. Now, we have a way to compare the “degree” of compactness using the
Definition 16: For a metric space 



Remark 17: One may wonder what this “entropy” has to do with thermodynamic or information entropy. It turns out, this naming convention only primarily has to do with the presence of the logarithm. A followup question is why log shows up so often. David Tong has a nice answer to this question in the context of statistical Physics:
Why do we take the log in the definition? One reason is that it makes the numbers less silly.
Indeed, in statistics, we take asymptotes so much that our numbers must eventually get “silly” (both in the sense of getting sillily large and sillily small).
Remark 18: We can now compare the “complexity” or “size” of two compact sets by comparing their metric entropies. A deeper answer to why we take logs has to do with the fact that by taking logs, we get more precise control over the complexity of our sets. In nonparametric statistics, a natural way to construct consistent estimators in infinite dimensional parameter spaces is to use “sieve” estimation where for each finite
Remark 19: As a bit of a teaser, we can be even more specific about why the logarithm is the right transformation to make our analysis of error precise. A lot of non-parametric theory assumes that the random variables we’re dealing with are “sub-gaussian” in the sense that ![\mathbb P(|X - \mathbb E[X]| > t) \leq A\exp(-vt^2)](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%28%7CX+-+%5Cmathbb+E%5BX%5D%7C+%3E+t%29+%5Cleq+A%5Cexp%28-vt%5E2%29&bg=eeeeee&fg=666666&s=0&c=20201002)
![\mathbb P(|X - \mathbb E[X]| > t) \leq A\exp(-vt)](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%28%7CX+-+%5Cmathbb+E%5BX%5D%7C+%3E+t%29+%5Cleq+A%5Cexp%28-vt%29&bg=eeeeee&fg=666666&s=0&c=20201002)


Not only does this notion of metric entropy allow us to quantify the size of compact sets precisely, it also gives us a strategy to quantitatively characterize how “close” non-compact sets are to being compact. For example, if a set 

