Suppose we have some random vector  following some (non-degenerate in the sense of having positive definite covariance) multivariate Gaussian distribution with mean
following some (non-degenerate in the sense of having positive definite covariance) multivariate Gaussian distribution with mean  and covariance matrix
and covariance matrix

It is a well known fact that the conditional distribution of  is given by another multivariate Gaussian with mean and covariance matrix given respectively by
is given by another multivariate Gaussian with mean and covariance matrix given respectively by
![\mathbb E[Y | X] = \mu_Y + \Sigma_{xy}^T\Sigma_{xx}^{-1}(X - \mu_X)](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY+%7C+X%5D+%3D+%5Cmu_Y+%2B+%5CSigma_%7Bxy%7D%5ET%5CSigma_%7Bxx%7D%5E%7B-1%7D%28X+-+%5Cmu_X%29&bg=eeeeee&fg=666666&s=0&c=20201002)

These formulas have some nice intuition behind them, especially when they interpreted as Bayesian rules for updating beliefs about  upon seeing some relevant data,
upon seeing some relevant data,  . The top formula is basically saying that we should move in the direction of the best predictor given , and our update should be more extreme the more unexpected is. The bottom formula basically says that information about must reduce our uncertainty about .
. The top formula is basically saying that we should move in the direction of the best predictor given , and our update should be more extreme the more unexpected is. The bottom formula basically says that information about must reduce our uncertainty about .
The usual proof of this is a tedious and boring calculation involving expressing a matrix inversion in terms of a Schur complement (this is not unlike how the typical proof Frisch-Waugh-Lovell is also just a computation with Schur complements). Here, I want to present an alternative proof along lines I feel are more typical to how econometricians do stats.
By demeaning our multivariate Gaussian, we will WLOG assume that ![\mathbb E[X] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+0&bg=eeeeee&fg=666666&s=0&c=20201002) and
and ![\mathbb E[Y] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY%5D+%3D+0&bg=eeeeee&fg=666666&s=0&c=20201002) . Then by one definition of a multivariate Gaussian distribution, we have there are full rank matrixes
. Then by one definition of a multivariate Gaussian distribution, we have there are full rank matrixes 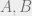 such that
such that  and
and  for some
for some  such that
such that

We will need two technical exercises to justify a few operations on submatrices:
Exercise 1: Show that if  is a positive definite matrix, then is invertible and
is a positive definite matrix, then is invertible and  is also positive definite (Hint: use the spectral theorem).
is also positive definite (Hint: use the spectral theorem).
Exercise 2: Show that if is positive definite, then any square sub-matrix is also positive definite (Hint: use the definition that is positive definite if and only if  for all vectors
for all vectors  ).
).
With these two in hand, it is possible to prove:
Exercise 3: Show that follows another Gaussian distribution and ![\mathbb E[Y | X]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY+%7C+X%5D&bg=eeeeee&fg=666666&s=0&c=20201002) is linear in (Hint: use the conditional density formula. It suffices to show that the density must be proportional to a multivariate Gaussian density without showing what that density is).
is linear in (Hint: use the conditional density formula. It suffices to show that the density must be proportional to a multivariate Gaussian density without showing what that density is).
Remark 4: Hopefully, the above exercise makes clear why the typical proof is to take inverses using a Schur complement. It would be the obvious next step after the conclusion of the exercise. However, I will proceed in a way that I think is more conceptually stimulating and less computationally burdensome.
We can now write the relationship between  as a linear regression, giving us
as a linear regression, giving us

Then we are just solving the least squares problem:
![D = \mathbb E[YX^T] \mathbb E[X X^T]^{-1} = B A^T (A A^T)^{-1}](https://s0.wp.com/latex.php?latex=D+%3D+%5Cmathbb+E%5BYX%5ET%5D+%5Cmathbb+E%5BX+X%5ET%5D%5E%7B-1%7D+%3D+B+A%5ET+%28A+A%5ET%29%5E%7B-1%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Exercise 3 shows us that the conditional expectation is linear, so it is equivalent to the best leaner predictor, so ![\mathbb E[Y | X] = DX = B A^T (A A^T)^{-1} X](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY+%7C+X%5D+%3D+DX+%3D+B+A%5ET+%28A+A%5ET%29%5E%7B-1%7D+X&bg=eeeeee&fg=666666&s=0&c=20201002) . Additionally, we have that
. Additionally, we have that 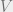 is Gaussian and uncorrelated with and hence independent of . So
is Gaussian and uncorrelated with and hence independent of . So  . But we also have that
. But we also have that


which is the desired conditional covariance formula.
I will conclude by teasing a somewhat applied example (although admittedly, I don’t know the algorithms I’m referencing with any depth). Note that the conditional covariance formula above is nothing more than the Schur complement of  , and it can be shown that if we write:
, and it can be shown that if we write:

we have that  . Suppose
. Suppose  . Then
. Then  is a diagonal matrix (since a matrix is diagonal if and only if its inverse is diagonal). The upshot is that if is multivariate Gaussian system with
is a diagonal matrix (since a matrix is diagonal if and only if its inverse is diagonal). The upshot is that if is multivariate Gaussian system with  , then we have that
, then we have that

This nice property partially explains the popularity of a Gaussian assumption in the probabilistic graphical models literature. In particular, the above shows that an undirected graph where each component of gets a node, and each pair of nodes  has an edge between them if and only if
has an edge between them if and only if  is a valid Markov random field representing the dependence structure of . This construction allows us to use general purpose exact and approximate inference algorithms on variables in , and these sort of ideas eventually motivate the actual algorithms that housekeeping robots and self driving cars use.
is a valid Markov random field representing the dependence structure of . This construction allows us to use general purpose exact and approximate inference algorithms on variables in , and these sort of ideas eventually motivate the actual algorithms that housekeeping robots and self driving cars use.
Published by statsmodel
Aspiring economist; statistics enthusiast.
View all posts by statsmodel
