In a previous post, we showed how the maximum likelihood estimator can be motivated by the fact that if a distribution belongs to some parametric model 

![\theta_0 = \mathrm{argmin}_{\theta \in \Theta}\, D(f(x | \theta_0) || g(x | \theta)) = \mathrm{argmin}_{\theta \in \Theta}\, \mathbb E_{x \sim f(x | \theta_0)}[ g(x | \theta)]](https://s0.wp.com/latex.php?latex=%5Ctheta_0+%3D+%5Cmathrm%7Bargmin%7D_%7B%5Ctheta+%5Cin+%5CTheta%7D%5C%2C+D%28f%28x+%7C+%5Ctheta_0%29+%7C%7C+g%28x+%7C+%5Ctheta%29%29+%3D+%5Cmathrm%7Bargmin%7D_%7B%5Ctheta+%5Cin+%5CTheta%7D%5C%2C+%5Cmathbb+E_%7Bx+%5Csim+f%28x+%7C+%5Ctheta_0%29%7D%5B+g%28x+%7C+%5Ctheta%29%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
The reason why MLE works (under suitable regularity conditions), then, is that the quantity to be minimized on the right hand side can be directly estimated in the data via the analogy principle. Actually, this idea of characterizing parameters as solutions to some variational problem is quite general, and one natural way to produce the corresponding variational problem is by measuring the distance between distributions via some quasipseudometric.
For now, let us restrict ourselves to distributions absolutely continuous with respect to some measure (i.e. distributions with densities). One quasimetric we have already considered for this setting is the KL-divergence used for MLE:

While this is a natural distance measure from an information theoretic perspective, other metrics may be more relevant for other settings. For example, in the 

On the other, if we care about more about 

Exercise 1: Show that the Hellinger and total variation metrics are true metrics by checking the axioms.
Once we have multiple choices of distance measures, a useful exercise is to compare the topologies they generate. In particular, we want to know if convergence in one metric automatically implies convergence in another. If it can be shown that for two metrics 

for some 



Exercise 2: Show that 
Others are harder, as evidenced by the fact that they are named after people:
Proposition 3 (Pinsker’s inequality):

The difficulty of this proof stems from the fact that both the absolute value and the logarithm showing up in these distance measures are reasonably nonlinear functions. In what follows, I present two proofs of Pinsker’s inequality. The first is from this textbook, where I first encountered it, and the second is my modification, which I find to be more pedagogically useful.
Proof 1: It suffices to consider the case where 



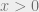

Now, we get


where the inequality in the second to last step is Cauchy-Schartz.
I don’t like the proof mainly because I find it too “authoritarian” in the sense that some higher being tells you that 

Proof 2: We make the observation that

It’s not terribly unrealistic that a mere mortal can make this step, since at the end of the day, we want to somehow take care of the largest non-linearity in the definition of KL-divergence, the 

The second factor, then, will just be the square root of KL divergence as desired, while the first term can be further analyzed to yield a constant bound. Unfortunately, this does not quite work. The issue is that the square root is not defined for negative quantities, so the Cauchy-Schartz step above is invalid. At this point, we use the fact that 








Now, to show that the integral above is bounded in a way that does not depend on 
Exercise 4: Show that 
Now by concavity, it can be bounded above by its first order Taylor expansion, which gives

since 
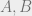

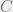

Exercise 5: Optimize the point at which we expand around to get the constant of 
Proofs in the textbook style above are efficient for demonstrating that a result is true without providing much information about how a result was discovered. It is entirely reasonable that textbooks tend to opt for the former style, since proofs of the second style can be much longer to write down.
It seems to me, however that there are two main places where we might want to opt for a style 2 proof. The first is in proving important, but nontrivial results. This is because it is my view that textbook authors have a responsibility to show that the important results of their field are not the result of some inaccessible insight, but the result of careful thinking combined with the hard work necessary to stumble upon the handful of difficult, but ultimately accessible, discoveries required to make progress. The second setting where I think it is helpful to write proofs in the style of proof 2 above is in more introductory texts. In these settings, taking the time to fully motivate all of the optimizations and tweaks required to make the proof work has the added benefit of demonstrating to the reader how to think about problems. For relative beginners, the marginal benefit of this is probably high enough to justify the extra word count.
A good binary measure of whether someone deeply understands a proof is whether they are able to turn a style 1 proof into a style 2 proof. This is why this blog is such a useful tool for me. It has served as an excellent instrument for forcing myself to get to this level of understanding. While it is sometimes too tempting to be lazy and just present a top down textbook style proof, when possible, I try to hold myself to the standard of writing proofs of the second style as much as possible here.
