A popular musing about math is to ask whether an advanced alien civilization would have the same mathematics as us. A common answer is that while the language and symbols would almost certainly be different, the most important underlying concepts would be isomorphic.
A quip I had after my first undergrad statistics class is that the real question we should be asking is whether an alien civilization would have a statistics that is even remotely similar to ours. The frustration I was getting at here is the fact that so much of what we learned seemed arbitrary and just based on the modeling decisions made by one or two statisticians. For example, would an alien civilization favor Bayesian or frequentist statistics? Maybe neither?
My current view is that these sorts of questions distract from a core of ideas so natural that if anyone who believes that aliens have isomorphic mathematics, would have to conclude that they have at least nearly isomorphic statistics. In the next series of posts, I hope to convince readers of this position. I will probably fail at this, but maybe along the way, we can learn some statistics.
The core idea behind much of statistics is that when a phenomenon is sufficiently regular (both in the sense of occurring over and again and in the sense of being “well behaved” in a technical sense), collecting more and more data should allow us to understand it arbitrarily well. The key way that this intuition gets formalized is by studying the “convergence” behavior of various random processes. We already saw this to an extent in the form of the central limit theorem. In that case, the the phenomenon we wanted to study was the mean of a distribution. The regularity was that we assumed that we could get data from the same distribution over and again, and that the distribution at least had finite variance. The convergence we obtained was a concept known as convergence in distribution. In one sense, the result is remarkably general. We had to make relatively few assumptions about the underlying distribution to get a very precise result. In another sense, it seems remarkably weak. The only phenomenon it allows us to study right now is expectations, and it requires us to adopt a certain view of convergence.
We will begin by studying convergence in more detail. To do so, we will need a more precise language. I will spend this post walking through some of the basics of how mathematicians formalize the intuitive notion of probability. To do this properly, we need to first introduce the concept of the -field:
Definition 1: Let be some set. A -field, is a collection of subsets of such that
If , then (closure under complements).
If , then (closure under countable union).
The backslash here is set difference. Such a concept seems unnatural, but is needed in some form. Intuitively, -fields correspond to our definition of sets that are well behaved enough to warrant our study. Studying every possible set will turn out to be too difficult since it will in general lead to paradoxes. We therefore will need to restrict our study somewhat, but hopefully as little as possible. In particular, 2 and 3 guarantee that we can do logic on whatever collection we restrict our attention to since set complements corresponds to logical not, and set unions correspond to logical or. Using De Morgan’s laws, “or” and “not” are sufficient to construct other basic logical operations. But given this, one might ask why we require countable union, and not just finite union. This is largely motivated by the fact that it will allow us just enough structure to ensure that we will be able to study sequences we construct. Note that countable additivity is understood to include finite additivity as a special case (just set for all sufficiently large ). Sets will be called measurable which is suggestive of the interpretation that is our model of things that are well behaved enough for us to study. We can now define a probability space.
Definition 2: A probability space is a triple where is a -field on , and is a function that takes a measurable set to a probability satisfying:
.
If are mutually disjoint (i.e. for ), then
The elements are called events. 1 corresponds to the idea that something from has to have happened. This tells us that we have to design our probability spaces to model all possible outcomes. 2 captures an intuition we have about how probabilities should behave. If I roll a 6 sided die, the probability I roll a 1 or a 2 is the probability that I roll a 1 plus the probability I roll a 2. At this point, it should be noted how important our definition of was. It exactly corresponds to what was needed to to ensure the operations used in defining are well defined. I will adopt the convention that is a generic element of As it stands, this definition seems sort of barren. We are missing a lot of other familiar facts that all probabilities should satisfy. The following should assuage these concerns:
Exercise 3: Show that probability spaces satisfy the following:
(null empty set)
(probability of complements)
If , then (monotonicity)
For arbitrary , (union bound)
Another useful property of -fields is that they are monotone in the following sense:
Lemma 4: Let be such that for all . Then .
Proof: The idea is to study related sets where we can use countable additivity. To that effect, construct . It is clear that , and . Additionally, since the are nested, we have that all the are disjoint. Then
.
Exercise 5: The above result is called continuity from below. Prove continuity from above: If is such that , then . (Hint: Use De Morgan’s laws to reduce this to the assumptions of lemma 4)
For the purposes of many results, it will be no loss to consider settings where some desired property holds for every except for some exceptional set such that . When a property satisfies this, we say that it holds almost surely or for almost all .
At this point, textbooks about probability theory will walk through chapters of results on constructing probabilityspaces. I will spare you the gory details here. As an antidote to the abstractness here, I will give an example to play around with.
Example 6: Let . Let be the collection of all subsets of that can be constructed using countable unions and intersections of the open subsets of . Let and . This is the uniform measure on and may be recognized as corresponding to the uniform distribution on .
Exercise 7: Show that the above is a probability space. In addition, show that every countable subset of is in and in fact, has probability 0. Conclude that the probability of drawing a rational number from is 0.
Given a probability space, a function is measurable if (i.e. the preimage of under is measurable) for each open set . So measurable functions are just those functions that play well with both the topology of the real number line and the measurable sets at the same time.
Definition 8: A random variable is any measurable function .
For an arbitrary topology, the Borel -field is the -field comprising all sets that can be constructed as countable unions and intersections of open and closed sets (show that this is indeed a -field). Sets in this -field are called Borel measurable, or Borel sets. If is Borel measurable, then we will say that . Hopefully, it is now immediately obvious why we defined random variables in this way: it is precisely what was needed to ensure that probabilities of the most well behaved sets (in topology, the open sets are intuitively the ones that are the most normal) are well defined. Thinking about random variables as functions is useful because it allows us to distinguish between the random variable and its realization. The random variable itself is the entire function and associated probability of taking on various values while the realization, is the evaluation of at a particular . This single distinction is one of the main reasons for the long detour through technical definitions. Usually, thinking about whether functions or sets are measurable is not needed for everyday users of probability. It’s amazingly difficult to construct examples of non-measurable objects. However, the distinction between random variables and realizations will be useful, and hence, I would like to make sure readers at least understand it at a conceptual level. The following result is trivial (in the precise sense of following straight from definitions) if you use the right definition of continuity. Showing it is a good check of if you grasp the definition sufficiently well.
Exercise 9: Show that if are random variables, and is continuous, then is a random variable.
Often, we can ignore the underlying probability space altogether and just look at how the random variable itself behaves. We call the distribution of the mapping for each Borel set . In particular, it suffices to know the familiar c.d.f. . I am now able to define two of the most useful concepts of convergence:
Definition 10:
A sequence of random variables converges in probability to (denoted ) if for every , there exists such that for all , (in light of exercise 7, is a random variable. The set is open and hence the above probability makes sense).
A sequence of random variables converges almost surely to (denoted if (note here the usefulness of this concept of realization. More rigorously, the probability on the left is . The definition thus presupposes the measurability of this set).
Lemma 11:.
Proof: Let . Clearly . Define . Translating the set notation into logic, is the set of where infinitely often. It is clear that if this is true, hence . By monotonicity and the definition of almost sure convergence, this means . Using continuity from above, we have . Finally, note that . Thus, using monotonicity one more time , which is exactly the definition of convergence in probability.
A natural question to ask is whether or not the opposite implication holds. The following exercise asks you to show that indeed, it does not.
Exercise 12 (Typewriter sequence): Consider again, the uniform probability measure. Let
for . Show that along the path , for each (where here is understood to be the constant function that maps everything to ), but
The definition of almost sure convergence is not easy to work with. It asks about the probability of some sequence of random variables converging. Convergence and probability are difficult enough concepts on their own, so thinking about both at the same time can be daunting. The following result is the most common strategy for showing convergence almost surely:
Lemma 13 (First Borel-Cantelli Lemma): Let be events in a probability space. Suppose . Then .
Proof: An equivalent condition to is that . Using continuity from above, we have . But now, using countable subadditivity, . Putting these together gives us exactly that .
To see why this is exactly what is needed to show convergence almost surely, notice that taking the to be as in the proof of Lemma 11 and , convergence almost surely is exactly the requirement that . The following exercise can be used to formalize the famous idea that “a monkey hitting random typewriter keys for an infinite amount of time will eventually write the complete works of William Shakespeare” (as well as the complete works of William Shakespeare with a single typo, etc).
Exercise 14 (Second Borel-Cantelli Lemma): Events are called independent if (check that in the finite case, this corresponds to the intuition we are used to). Prove the following partial converse to the Borel-Cantelli lemma: Suppose for independent events . Then . (Hint: Use De Morgan’s law to convert to a similar statement about . Use the definition of independence to get a statement about a certain product of probabilities. Next, use the fact that for all . This fact will help turn a product into a sum. Conclude by using the assumption we made about the sum.)
My roommate said I should include more figures so here you go: a modern monkey at a modern typewriter.
I will close out this post by defining expected value, as this is the operation under which many of the standard convergence results will hold. To begin, let us consider the intuitive definition of expected value, or mean, in the case when only takes on finitely many values. Suppose, for instance, I flip a coin with probability of landing heads and probability of landing tails. Let if it lands heads and if it lands tails. Then intuitively, we want to define expected value so that the mean of is . Similarly, the expected value of a fair die roll should be . More generally, the formula we want to use is the probability weighted sum of values takes on. Formally,
Definition 15: We say that a random variable is discrete if it takes on a countable number of values. We say that it is simple if it takes on a finite number of values. For discrete random variables, we define the expected value of taking on values (with possibly infinite) different values to be
provided that
At first glance, it may be somewhat confusing why we need to restrict that the expected value sums to a finite number. However, if while , then a famous theorem of Riemann will show that the order of the can be rearranged to make the sum any real number, or even . In this case, it is not very sensible to even talk about expectations since it is sensitive to how we order the possible values of . Expectations are well behaved because they satisfy the following important property:
Lemma 16 (Linearity of Expectations): Let be arbitrary discrete random variables on a probability space. Then .
Proof:
. As an exercise, justify the second equality more rigorously.
We would now like to extend the definition of integration to arbitrary measurable functions. The basic idea will be that measurable functions can be arbitrarily well approximated by simple functions. For example, we can show a result such as the following.
Proposition 17 (Approximation from below by simple functions): Let be a non-negative measurable function. Then there exists a sequence of simple functions such that and almost surely.
Proof: In fact, it is possible to get sure convergence. Define to take on values in . Let except for the . Let .
The above construction is a common theme in the theory of integration in general and probability in general: in order to prove something about expected values (which turn out to be integrals) the following road map often works:
First show the fact for indicator functions
Extend to simple functions using linearity
Extend to non-negative functions by approximation from below
Extend to arbitrary functions by the fact that where and .
Motivated by this type of construction, we can define expectations in general:
Definition 18: Let be an arbitrary random variable. Then
When the distribution of has a p.d.f. (I will not rigorously define this here, but assume that the reader is familiar) for example, this definition gives precisely that . Readers with some familiarity with real analysis may recognize this as a special case of the definition of the Lebesgue integral. Approximation from below means that the linearity of expectations carries over from the discrete case to the general case. Additionally, other familiar properties of integrals are preserved by this definition of expectations. There are three (four including the corollary) classical results that most contribute to the usefulness of this definition of expectation. Their proofs are somewhat long and technical, so I omit them here (although Wikipedia actually proves all of them if you are interested)
Theorem 19 (Monotone Convergence): Suppose are such that and for almost all . Then .
Theorem 20 (Fatou’s Lemma): Let be such that . Then
Corollary 21 (Reverse Fatou’s Lemma): Let be such that there is a non-negative for all with . Then .
Theorem 22 (Dominated Convergence): Let be such that there is non-negative for all with . Assume further that . Then .
Monotone convergence tells us if the process by which the converge to is sufficiently well behaved, integration and taking limits may be swapped. Fatou’s lemma tells us that when swapping integrals and liminfs in general, mass may be lost, but not created. The Reverse Fatou Lemma gives some conditions under which mass can also not be created for limsups. Finally, dominated convergence tells us that if we can find some function that dominates the sequence (in the sense of being larger in absolute value) and this dominating function is well behaved, then this good behavior is passed on to the sequence it dominates. In practice, dominated convergence is the most commonly seen directly applied result.
In this post, I introduced a wide array of technical machinery that seems a bit disparate at this point. In a sequel, I will be able to discuss the laws of large numbers, which tie these concepts together. The long term goal will be to use these results to motivate a general framework for coming up with statistical estimators.



, then
(closure under complements).
, then
(closure under countable union).





![\mathbb P: \mathcal F \to [0,1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%3A+%5Cmathcal+F+%5Cto+%5B0%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
.
are mutually disjoint (i.e.
for
), then


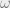
(null empty set)
(probability of complements)
, then
(monotonicity)
,
(union bound)












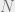

![\Omega = [0,1]](https://s0.wp.com/latex.php?latex=%5COmega+%3D+%5B0%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002)









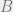







converges in probability to
) if for every
, there exists
,
(in light of exercise 7,
is a random variable. The set
is open and hence the above probability makes sense).
if
(note here the usefulness of this concept of realization. More rigorously, the probability on the left is
. The definition thus presupposes the measurability of this set).



















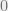

























![\mathbb E[X] = \sum_{k=1}^n x_k \mathbb P(X = x_k)](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+%5Csum_%7Bk%3D1%7D%5En+x_k+%5Cmathbb+P%28X+%3D+x_k%29&bg=eeeeee&fg=666666&s=0&c=20201002)



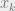


![\mathbb E[X] + \mathbb E[Y] = \mathbb E[X + Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BY%5D+%3D+%5Cmathbb+E%5BX+%2B+Y%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
![\mathbb E[X] + \mathbb E[Y] = \sum_{i=1}^n x_i \mathbb P(X = X_i) + \sum_{j=1}^m y_j \mathbb P(Y = y_j)](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BY%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5Cmathbb+P%28X+%3D+X_i%29+%2B+%5Csum_%7Bj%3D1%7D%5Em+y_j+%5Cmathbb+P%28Y+%3D+y_j%29&bg=eeeeee&fg=666666&s=0&c=20201002)


![= \mathbb E[X+Y]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb+E%5BX%2BY%5D&bg=eeeeee&fg=666666&s=0&c=20201002)







where
and
.
![\mathbb E[X] = \sup\{\mathbb E[X^*]: X^* \text{ simple}, X^* \leq X\}](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+%5Csup%5C%7B%5Cmathbb+E%5BX%5E%2A%5D%3A+X%5E%2A+%5Ctext%7B+simple%7D%2C+X%5E%2A+%5Cleq+X%5C%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
![E[X] = \int_{-\infty}^\infty x f_X(x)\,\mathrm dx](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+x+f_X%28x%29%5C%2C%5Cmathrm+dx&bg=eeeeee&fg=666666&s=0&c=20201002)

![\mathbb E[X_n] \to \mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX_n%5D+%5Cto+%5Cmathbb+E%5BX%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

![\mathbb E[X] \leq \liminf_{n\to\infty} \mathbb E[X_n]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbb+E%5BX%5D+%5Cleq+%5Climinf_%7Bn%5Cto%5Cinfty%7D+%5Cmathbb+E%5BX_n%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

![\mathbb E[Y] < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY%5D+%3C+%5Cinfty&bg=eeeeee&fg=666666&s=0&c=20201002)
![\limsup_{n\to\infty} \mathbb E[X_n] \leq \mathbb E[\limsup_{n\to\infty} X_n]](https://s0.wp.com/latex.php?latex=%5Climsup_%7Bn%5Cto%5Cinfty%7D%C2%A0%5Cmathbb+E%5BX_n%5D+%5Cleq+%5Cmathbb+E%5B%5Climsup_%7Bn%5Cto%5Cinfty%7D+X_n%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

