I take a break from my usual pure theory to present something a little more applied. Suppose you estimate the OLS model

where 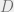 is a dummy variable and
is a dummy variable and  is continuous. For conceptual simplicity, suppose that the conditional expectation function truly as specified above and that the errors are homoskedastic. Upon estimating this model, you find out that not only is the interaction term not statistically significant, but so is
is continuous. For conceptual simplicity, suppose that the conditional expectation function truly as specified above and that the errors are homoskedastic. Upon estimating this model, you find out that not only is the interaction term not statistically significant, but so is  . This is a bit surprising since if you estimated the model
. This is a bit surprising since if you estimated the model

you find that is highly significant. Additionally, the point estimates are totally different anyways. This points to the first subtlety of interpreting interaction coefficients. In the top model, in population, we have that
![\beta_d = \mathbb E[Y | X = 0, D = 1] - \mathbb E[Y | X = 0, D = 0]](https://s0.wp.com/latex.php?latex=%5Cbeta_d+%3D+%5Cmathbb+E%5BY+%7C+X+%3D+0%2C+D+%3D+1%5D+-+%5Cmathbb+E%5BY+%7C+X+%3D+0%2C+D+%3D+0%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
By contrast, in the bottom regression, we have
![\beta_d = \mathbb E[Y | D = 1] - \mathbb E[Y | D = 0]](https://s0.wp.com/latex.php?latex=%5Cbeta_d+%3D+%5Cmathbb+E%5BY+%7C+D+%3D+1%5D+-+%5Cmathbb+E%5BY+%7C+D+%3D+0%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Even if we go so far as to assume that the population CEF is correctly specified by the interactions model, under unequal slopes, these two values are not in general the same. In fact, the only way they are the same is if either
![\mathbb E[X|D] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%7CD%5D+%3D+0&bg=eeeeee&fg=666666&s=0&c=20201002) for
for 
 in population
in population- Both of the above fail, but in a way that happens to just cancel out.
Now, suppose you find yourself in the situation (as I did) where variation in was assigned according to an experiment. The experiment worked in the following way. First, a proportion  of all units are chosen at random from the population to be part of the experiment. Those units in the experiment are randomly assigned a value of from some set
of all units are chosen at random from the population to be part of the experiment. Those units in the experiment are randomly assigned a value of from some set ![[a,b] \ni c](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D+%5Cni+c&bg=eeeeee&fg=666666&s=0&c=20201002) (in fact, assume
(in fact, assume ![\mathbb E[X] = c](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+c&bg=eeeeee&fg=666666&s=0&c=20201002) , which makes the analysis somewhat simpler in a bit). The rest of the units were assigned by default to a value of c. You now first run the model only on those units tagged as in the experiment. When you run the interacted model, you find that estimate of has a high variance. Your idea is then to use all of the other units to decrease the variance of the estimator. Does this work? To my surprise, the standard errors hardly changed at all.
, which makes the analysis somewhat simpler in a bit). The rest of the units were assigned by default to a value of c. You now first run the model only on those units tagged as in the experiment. When you run the interacted model, you find that estimate of has a high variance. Your idea is then to use all of the other units to decrease the variance of the estimator. Does this work? To my surprise, the standard errors hardly changed at all.
Since a model with interaction terms is equivalent to running OLS separately on each subsample, it suffices to analyze the standard errors of the intercept term on a single OLS model. I assume sampling of the following form. There is a fixed number  of observations where varies. Additionally, we have some sample
of observations where varies. Additionally, we have some sample  of observations where is fixed to be
of observations where is fixed to be ![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=eeeeee&fg=666666&s=0&c=20201002) from the first sample, and
from the first sample, and  is drawn from the same distribution as the first sample (this is why it is important that is determined experimentally). What is the asymptotic behavior of the variance as
is drawn from the same distribution as the first sample (this is why it is important that is determined experimentally). What is the asymptotic behavior of the variance as  ? Recall that for homoskedastic (and correctly specified) OLS, the variance estimator is given by
? Recall that for homoskedastic (and correctly specified) OLS, the variance estimator is given by

We are in particular interested in the 1,1 coordinate of the above matrix which I rewrite:

Denote by  the variance of in the original observations. Since sample variances and moments are variances and moments in their own rights, we can use the law of total variance to show that the above expression will converge in probability to
the variance of in the original observations. Since sample variances and moments are variances and moments in their own rights, we can use the law of total variance to show that the above expression will converge in probability to
![\hat\sigma^2_n\frac1n \dfrac{\mathbb E[X]^2}{\frac{n_1}{n_1+n_2}V_1} = \theta_p(1)](https://s0.wp.com/latex.php?latex=%5Chat%5Csigma%5E2_n%5Cfrac1n+%5Cdfrac%7B%5Cmathbb+E%5BX%5D%5E2%7D%7B%5Cfrac%7Bn_1%7D%7Bn_1%2Bn_2%7DV_1%7D+%3D+%5Ctheta_p%281%29&bg=eeeeee&fg=666666&s=0&c=20201002)
assuming ![\mathbb E[X] \neq 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%5Cneq+0&bg=eeeeee&fg=666666&s=0&c=20201002) (the numerator comes from the assumption that the additional data points identically have
(the numerator comes from the assumption that the additional data points identically have ![X = \mathbb E[X]](https://s0.wp.com/latex.php?latex=X+%3D+%5Cmathbb+E%5BX%5D&bg=eeeeee&fg=666666&s=0&c=20201002) ) where a sequence of random variables
) where a sequence of random variables 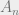 is said to be
is said to be  if both
if both  and
and  (and is
(and is  means that it is “bounded in probability”, or
means that it is “bounded in probability”, or  as
as  for some fixed, finite
for some fixed, finite 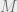 ). This is just a fancy way of saying that the random variable converges to a constant. In fact, in the above, since I assume my original sample of
). This is just a fancy way of saying that the random variable converges to a constant. In fact, in the above, since I assume my original sample of  to be fixed from the perspective of our asymptotics, the only non-constant stems from the uncertainty in estimating the standard errors. Therefore, I find exactly the result that increasing the sample past a certain point hardly changes the standard errors. This seems counterintuitive at first, but after some reflection, it seems to simply be a stark reminder that intercepts and interactions are not what we expect them to be.
to be fixed from the perspective of our asymptotics, the only non-constant stems from the uncertainty in estimating the standard errors. Therefore, I find exactly the result that increasing the sample past a certain point hardly changes the standard errors. This seems counterintuitive at first, but after some reflection, it seems to simply be a stark reminder that intercepts and interactions are not what we expect them to be.
Published by statsmodel
Aspiring economist; statistics enthusiast.
View all posts by statsmodel
