The first time I learned about the inner workings of the lfe package in R, I was told to read a paper by mathematician Israel Halperin called “The product of projection operators” (good luck finding it though. The only reason why I was able to access it is because I was sent a pdf at one point). This paper is concerned with generalizing a technique known as the method of alternating projections. Von Neumann first proved that by successively projecting a vector into two affine spaces, you converge on the projection into their intersection. Halperin managed to extend this result to remarkable generality, only requiring some minimal Banach space structure. I dutifully read this paper, but remember very little about the details. The level of generality was simply more than I really cared to take the time to understand, especially since my interest in it only went as far as understanding how an R package works.
It occurred to me recently that while the Halperin paper is difficult to grasp even at a conceptual level, the original von Neumann approach is so simple that extending it to an arbitrary number of projections in Euclidean space should be doable by fairly elementary means. Like most things I write, this probably won’t be of any use for the practitioner, except maybe to impart a sense of awe the next time a 20-way felm runs in mere minutes.
First some background. When I was first taught about the Frisch-Waugh-Lovell theorem, it was mostly framed as a formal justification for “adding controls” to linear regression models as a way to remove the confounding effects of other covariates. LFE uses the theorem in a completely different way: as a computational tool to speed up regressions. As a review, suppose we have a regression model:

Let ![\mathbb X = [\mathbb X_1\ \mathbb X_2]](https://s0.wp.com/latex.php?latex=%5Cmathbb+X+%3D+%5B%5Cmathbb+X_1%5C+%5Cmathbb+X_2%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

One version of Frisch-Waugh-Lovell tells us that an alternative expression for 

where


![\mathbb A = [A_1,A_2,\ldots,A_n]'](https://s0.wp.com/latex.php?latex=%5Cmathbb+A+%3D+%5BA_1%2CA_2%2C%5Cldots%2CA_n%5D%27&bg=eeeeee&fg=666666&s=0&c=20201002)
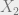

Exercise 1:
- Conclude from above that
where
is an orthonormal matrix and
- Additionally, if
is not collinear, then there are exactly
1’s in the above.



(Side note: typing that matrix was not fun).

In particular, because of the above properties, 




The sorts of models lfe excels at are ones of the form

where each 


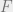

Exercise 2: Show that 



The fixed effects are usually not the parameters of interest, so we would like to estimate 
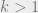
![F = [F_1,F_2,\ldots,F_k]](https://s0.wp.com/latex.php?latex=F+%3D+%5BF_1%2CF_2%2C%5Cldots%2CF_k%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Exercise 3: Show that if 



So at this point we know how to project into each individual 

The natural next question then is: does 
Theorem 4: Suppose 
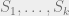


Orthogonality is a bit annoying to deal with, so let’s begin by proving something slightly easier.
Theorem 5: Suppose
For notational convenience, call 









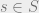



Exercise 6: For a nontrivial projection matrix 


Since each 
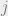

















Exercise 7: Show that 


We now add the orthogonality back in. All we need to do is show that if each 








In fact, as mentioned earlier, we have shown something even more remarkable.
Corollary 8: 
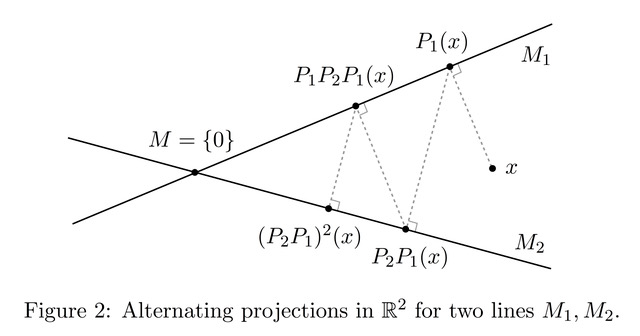
The rate of convergence of the alternating projections is at least linear. Roughly speaking, linear convergence means that there are some 







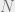
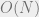




In hindsight, none of these facts should be particularly surprising. The visual intuition from figure 2 is the main insight, and we’ve just been playing around the symbols to fill in the technical details. Even the rate of convergence should not be terribly surprising. Alternating projections just repeatedly multiplying a matrix that is “<1” in some sense by itself repeatedly. Doing this with a real number <1 gives exactly linear convergence, so it is unsurprising that this extends to matrices with the proper construction.
I conclude by musing that this sort of proof is really only something that makes sense to publish in some sort of informal setting such as a blog. For those more interested in the theoretical aspects of the projections, there is little reason to not just read the Halperin paper. It doesn’t draw on any particularly deep math, is considerably more general, and is much more representative of the functional analytic tools of the trade necessary for further exploration. On the other hand, for the practitioner, there is little value added in knowing the gory details of the proof. In this case, I doubt knowledge about why alternating projections works would even be useful for debugging unexpected lfe behavior. Nonetheless, I hope I have impressed upon you some of the beauty and elegance of the inner workings of my most used R package.
Bonus Exercise: The derivation of FWL purely from matrix algebra is tedious/intimidating, but straightforward. This is not my favorite proof of FWL (my favorite can be found in Theorem 2.1 here), but I think it is still informative in its own right and worth doing exactly one time in your life. I will outline it here. Using the notations from earlier, we have:

The main difficulty in getting something more tractable is inverting the partitioned matrix. Fortunately, manipulating partitioned matrices is an extremely well studied problem. Let

and define 


(Hint: the proof is not hard, only tedious. The only trick is to write

and then solve/simplify). Now, use the Shur complement formula to show

(Hint: the idempotency of
