Over the past series of posts, I have described the standard theory for proving consistency in a large class of parametric models. While this is useful for showing that the estimators we dream up are actually doing the right thing, it’s still a bit unsatisfactory: so far, for any fixed dataset, we don’t have a good grasp on how close we should expect our estimators to be to the truth; we don’t yet have a satisfactory way to describe our uncertainty about our estimators.
At the outset, describing our “uncertainty” about a parameter seems like a hopelessly complex task. It looks like it should be such a multifaceted concept that we would need an extremely high dimensional (or even infinite dimensional) object to capture all of the relevant aspects. As it will turn out, however, in many of the well behaved settings used in real world applications, this problem of describing uncertainty will have so much regularity to it that it will essentially boil down to a single number for each parameter.
Before diving in to the theory, let’s take a step back and think conceptually about what it would mean to quantify uncertainty. A good start might be that uncertainty is a measure of the probability that our estimator is wrong about the true parameter. This seems like a reasonable start, but it can’t be the full story. If our distribution is continuous, the probability that we are wrong for most estimators is 1. So this criterion is too strict: we need to define something a bit less demanding. In particular, one reasonable relaxation is to think of uncertainty as the answer to the query: “How likely is my estimator to be within 


At this point, it may be obvious to readers that I am alluding to the typical asymptotic normality results that many statistical estimators enjoy. The fact that we’re talking about normality is a good hint that we will want to bring in a central limit theorem somehow, but it may not be obvious how we do this. In this post, I will walk through a sketch of how the typical argument goes.
Remark 1: I have been procrastinating writing this post for a while now largely because in writing an initial draft, it struck me that the theory for convergence in distribution contains a lot of technicalities that I had taken for granted. Furthermore, unlike most of what we’ve seen so far, I do not know of a satisfactorily elementary way to deal with these technicalities. There will therefore be more handwaving than usual in this post, but I will try to at least call out the exact points where the arguments sweep things under the rug.
The first idea that we will need for connecting the CLT to the estimators we’ve been describing so far is the following famous “device” of Cramer and Wold:
Theorem 2 (Cramer-Wold Theorem): A sequence of random vectors 



One of the directions in the above result should be clear:
Exercise 3: Show that if sequence of random vectors
The reverse direction is both more surprising and more technical to prove. Essentially, it follows from analyzing the characteristic functions of 

This theorem is incredibly powerful because it establishes that in proving asymptotic normality results, there is no loss of generality in focusing on the scalar case. Thus, for example, the usual i.i.d. central limit theorem immediately generalizes to arbitrary dimensions.
The next key idea we will need is that the continuous mapping theorem holds for convergence in distribution:
Theorem 4 (Continuous mapping in Euclidean space): If 


Proof Sketch: Let 
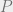


But this is equivalent to

But by the continuity of 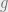


Remark 5: The basic idea of this proof is entirely topological in nature and thus works in much more abstract situations, provided the random variables are measurable with respect to the Borel 
Remark 6: The portmanteau theorem invoked in the above sketch is a fundamental result and gives a nice characterization of the topology of convergence in distribution. In particular, together with the Riesz-Markov-Kakutani representation theorem, it shows that the topology of convergence in distribution is exactly equal to a certain weak topology from linear functional analysis, and thus, much of the machinery of locally convex vector spaces can be used to answer questions about convergence in distribution.
With the following observation, the continuous mapping theorem immediately implies Slutsky’s lemma (a result so useful, that even University of Chicago economics undergrads learn its statement).
Exercise 7: Show that for some constant 


Exercise 8: Use the above to show Slutsky’s lemma: suppose 
provided that



(Hint: addition, multiplication, and division are all continuous binary operations)
Remark 9: This is the same Slutsky as the Slutsky decomposition from consumer theory. One of my favorite pieces of math history is that Slutsky was a Russian mathematician worked on mathematical economics up until about the time of the Bolshevik revolution when he suddenly developed an interest in probability theory.
With all of this machinery in place, we are finally ready to derive the interesting asymptotic normality results we’ve been building up towards. So far, the asymptotic normality theory we’ve looked at has all been restricted to linear situations. The CLT is about sample averages, which is a linear way to summarize data, and the Cramer-Wold device was about dot products, which are also linear. The idea for how to extend this to nonlinear settings is that we want to approximate nonlinear objects by linear ones. The question then becomes: when is this approximation a “good” one? But this question of when linear approximations are locally good is basically the definition of the derivative. In particular, we have
Proposition 10: A function 
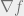

with 
If 

Theorem 11 (Delta method, part 1): If 


Proof: By continuous mapping for convergence in probability, 
Clearly, the above generalizes to the case where the range of 

where
Exercise 12 (Delta method, part 2): Show that if the above Taylor expansion is valid, and 


In particular, theorem 11 now immediately gives us an asymptotic distribution for sufficiently well behaved method of moments estimators.
Corollary 13: Consider a method of moments estimator using moment conditions ![\mathbb E[g(X;\theta)] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5Bg%28X%3B%5Ctheta%29%5D+%3D+0&bg=eeeeee&fg=666666&s=0&c=20201002)

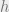
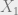
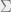

where 
Finally, we turn to the case of M-estimators. Recall that an M-estimator attempts to optimize an objective function 

![Q(\mathbb E[X], \theta_0)](https://s0.wp.com/latex.php?latex=Q%28%5Cmathbb+E%5BX%5D%2C+%5Ctheta_0%29&bg=eeeeee&fg=666666&s=0&c=20201002)



where 




Assuming all the relevant moments exist, and 
![\nabla_{\theta\theta} Q(\bar X_n, \bar\theta_n)^{-1}\overset{p}\to Q(\mathbb E[X], \theta_0)^{-1} \equiv H^{-1}](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%5Ctheta%7D+Q%28%5Cbar+X_n%2C+%5Cbar%5Ctheta_n%29%5E%7B-1%7D%5Coverset%7Bp%7D%5Cto+Q%28%5Cmathbb+E%5BX%5D%2C+%5Ctheta_0%29%5E%7B-1%7D+%5Cequiv+H%5E%7B-1%7D&bg=eeeeee&fg=666666&s=0&c=20201002)


![\Sigma = \nabla_{\theta,\mathbb E[X]} Q(\mathbb E[X];\theta_0)^T \mathbb V\mathrm{ar}(X) \nabla_{\theta,\mathbb E[X]} Q(\mathbb E[X];\theta_0)](https://s0.wp.com/latex.php?latex=%5CSigma+%3D+%5Cnabla_%7B%5Ctheta%2C%5Cmathbb+E%5BX%5D%7D+Q%28%5Cmathbb+E%5BX%5D%3B%5Ctheta_0%29%5ET+%5Cmathbb+V%5Cmathrm%7Bar%7D%28X%29+%5Cnabla_%7B%5Ctheta%2C%5Cmathbb+E%5BX%5D%7D+Q%28%5Cmathbb+E%5BX%5D%3B%5Ctheta_0%29&bg=eeeeee&fg=666666&s=0&c=20201002)
Theorem 13 (Asymptotic normality for sufficiently “regular” M-estimators): If 

Remark 14: The “sandwich” form of the asymptotic variance arises because

Exercise 15: Use the above result to formulate and prove conditions under which the maximum likelihood estimator is consistent and asymptotically normal. Use the information matrix equality to simplify the expression for the asymptotic variance.
Exercise 16: Suppose your likelihood model is incorrectly specified, but the smoothness and finite moment assumptions still hold. What does the MLE now converge to? What happens to the asymptotic variance under misspecification? (Hint: the asymptotic object the MLE converges to is related to an information projection)
When 
Before finishing this series on the basics of asymptotic statistics, I wanted to reexamine my initial goal when I started writing as well as provide some good starting points for further reading. In my first post in this series, I mused a bit about how much different an alien civilization’s statistics would be. My undergrad self would have probably answered “quite different”. This view is mostly driven by the fact that my first college statistics course talked a lot about philosophical disagreements like frequentist vs Bayesian frameworks for thinking about data, the (somewhat unnatural) interpretation of p-values, etc. However, this view probably emphasizes the differences in opinion too much and downplays the common threads that have been present throughout: that there is a lot of regularity in randomness, that samples are often sufficient to reasonably accurately characterize the population, and that by studying this regularity, we can construct approximately apples to apples comparisons between seemingly disparate phenomenon. Like with the any other branch of mathematics, the specific language might look different across different histories, but the laws of probability themselves are inescapable.
Finally, here is a list of texts for further study (these are just the texts I’ve learned from, so it is by no means comprehensive):
- Billingsley’s Probability and Measure is a classic text (and where I first learned measure theory). It’s a bit dense, the proofs are not always the most elegant, and the notation can be quite un-modern at times. Nonetheless, it is completely accessible to anyone with an undergraduate real analysis background and some persistence.
- A more modern book is Rick Durrett’s Probability: Theory and Examples, although I have not read through much of it and sadly, the link to a pdf of the book I once had no longer exists.
- My first course in mathematical statistics was from Jun Shao’s Mathematical Statistics (unfortunately, there does not seem to be an online copy, and I had to borrow it from my university’s library over winter break). Aside from the chapter on nonparametric statistics, it should be accessible after working through a text like Billingsley. The earlier chapters especially feature good discussions about many non-asymptotic questions I have neglected here such as some basic theory for exponential families and a discussion of things like sufficient statistics.
- This series has been largely inspired by Newey and McFadden’s 1994 handbook of econometrics chapter on large sample estimation. This chapter presents quite general results that try to tie together as many things into the same framework as possible, which makes for a fairly difficult read (although it should be doable if the books above are mastered). Much of these posts has been an attempt at reworking the main arguments presented there (as well as filling in some gaps) in a way that (hopefully) trades off a bit of generality for cleaner exposition.
- Measure theory isn’t all about probability – fully rigorous theories of integration usually take measure as a starting point. I have found no better textbook for introducing measure theory than Terrance Tao’s (publicly available) lecture notes. His writing style tends to emphasize how even seemingly crazy formulas usually have some natural and intuitive grounding. I’ve found this incredibly useful for demystifying math and making it less intimidating.
